
이번 글에서는 유저 플로우를 통해서 k8s가 내부적으로 어떻게 동작하는지 알아보겠습니다.
하나의 Pod이 뜰 때 각 k8s 오브젝트가 어떻게 상호작용하는지
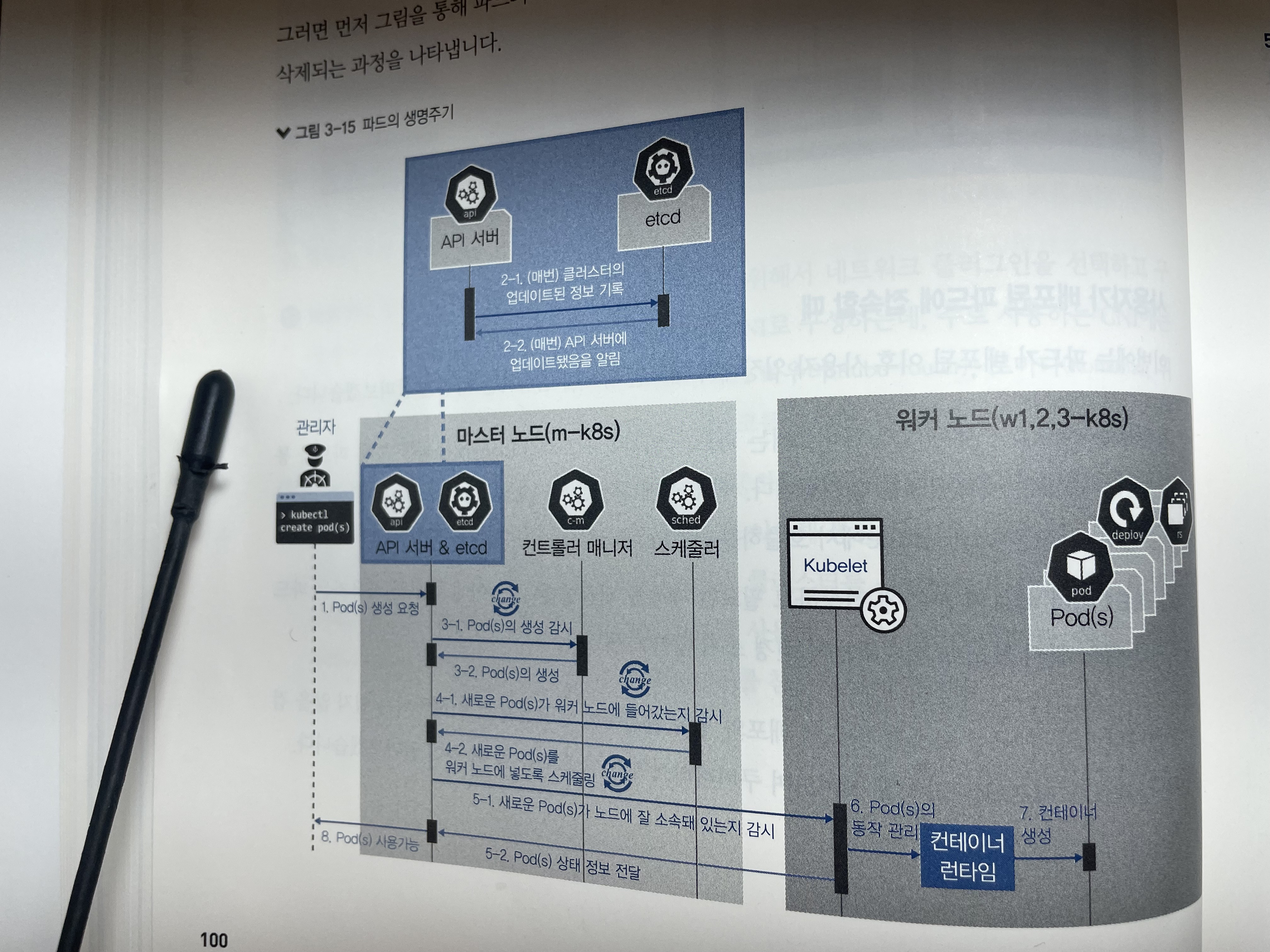
(Image source: 컨테이너 인프라 환경 구축을 위한 쿠버네티스/도커)
- kubectl을 통해 API 서버에 파드 생성을 요청합니다. 자세한 설명 - kubectl의 동작원리
- (업데이트가 있을 때마다 매번) API 서버에 전달된 내용이 있으면 API 서버는 etcd에 전달된 내용을 모두 기록해 클러스터의 상태 값을 최신으로 유지합니다. 따라서 각 요소가 상태를 업 데이트할 때마다 모두 API 서버를 통해 etcd에 기록됩니다. 자세한 설명 - etcd의 동작원리
- API 서버에 파드(정확히는 디플로이먼트) 생성이 요청된 것을 컨트롤러 매니저가 인지하면 컨트롤러 매니저는 파드를 생성하고, 이 상태를 API 서버에 전달합니다. 참고로 아직 어떤 워커 노드에 파드를 적용할지 는 결정되지 않은 상태로 파드만 생성됩니다. 자세한 설명 - 팟 생성 시 컨트롤러 매니저의 역할
- API 서버에 파드가 생성됐다는 정보를 스케줄러가 인지합니다. 스케줄러는 생성된 파드를 어떤 워커 노드에 적용할지 조건을 고려해 결정하고 해당 워커 노드에 파드를 띄우도록 요청합니다. 자세한 설명 - 스케쥴러와 kubelet의 역할
- API 서버에 전달된 정보대로 지정한 워커 노드에 파드가 속해 있는지 스케줄러가 kubelet으로 확인합니다. (공부한거랑 다름, -> 스케쥴러가 kubelet에 직접 호출하지 않고 kubelet도 watch 매커니즘으로 api 서버로부터 데이터를 받는 걸로 알고 있음)
- kubelet에서 컨테이너 런타임으로 파드 생성을 요청합니다.
- 파드가 생성됩니다.
- 파드가 사용 가능한 상태가 됩니다.
주인공들
- API 서버 (kube-apiserver)
- etcd
- 컨트롤러 매니저 (kube-controller-manager)
- 스케줄러 (kube-scheduler)
- kubelet
- 컨테이너 런타임 (Container Runtime)
위 주인공들은 k8s 클러스터링이 구축될 때 자동으로 초기화된다. minikube 통해서 구축할 때는 kube-system 이라는 네임스페이스에 팟으로 떠 있음.
1. API 서버 (kube-apiserver)
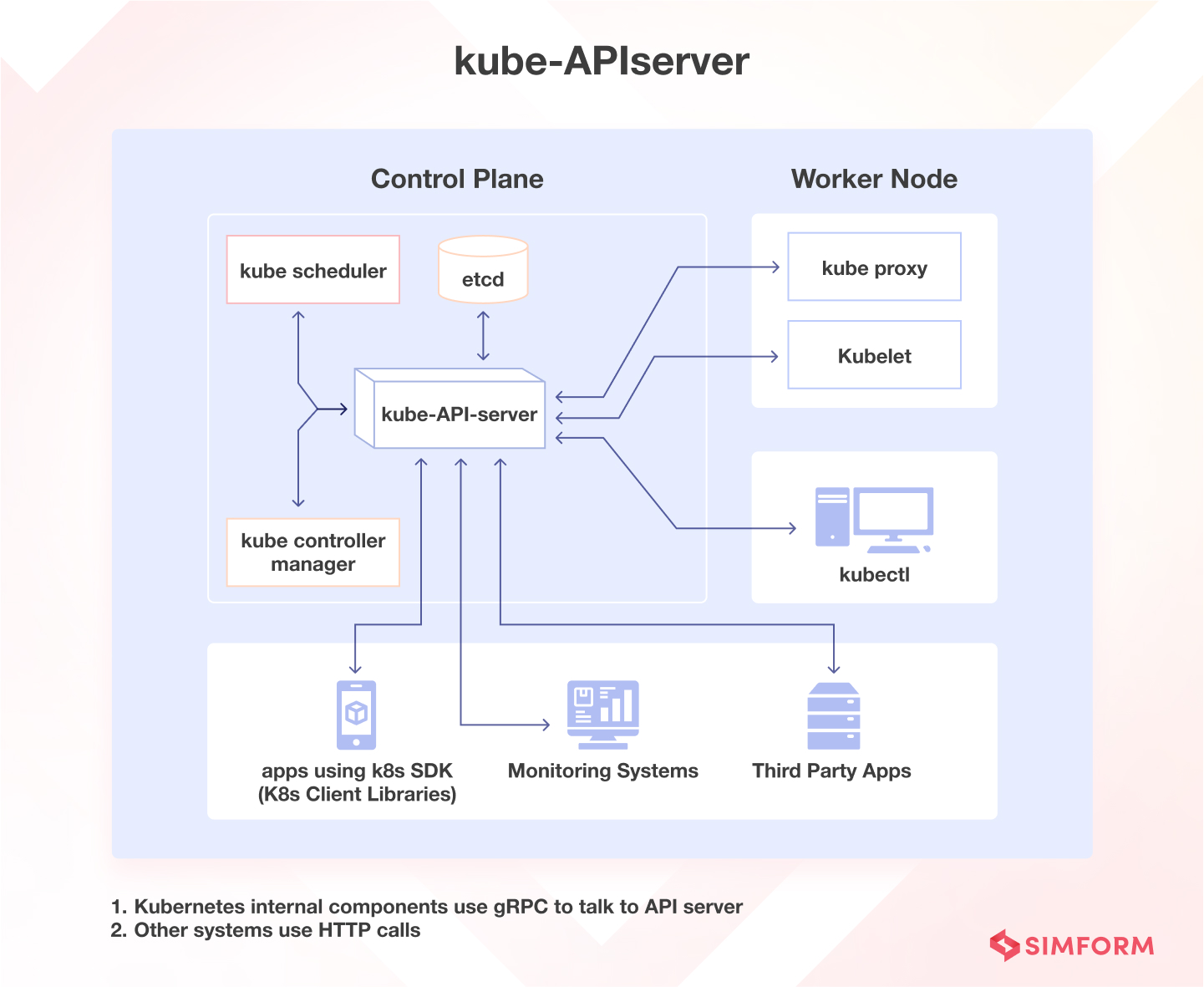
(Image source: https://www.simform.com/blog/kubernetes-architecture/)
역할:
- Kubernetes의 핵심 컴포넌트로, 클러스터의 모든 상태를 관리하고, 클라이언트와 통신합니다.
- RESTful API를 제공하여 외부 요청을 받아들이고 처리합니다.
- 모든 클러스터 내의 구성 요소와의 통신 허브 역할을 합니다.
상세 설명:
- 중앙 관리: API 서버는 클러스터의 중앙 관리 컴포넌트로, 모든 클러스터 구성 요소의 요청을 받아들이고, 이를 처리합니다.
- 인증 및 인가: 사용자와 시스템의 요청을 인증하고 인가하여 보안을 유지합니다.
- etcd와의 통신: 클러스터의 상태 정보를 etcd에 저장하고, 필요 시 이를 가져옵니다.
2. etcd
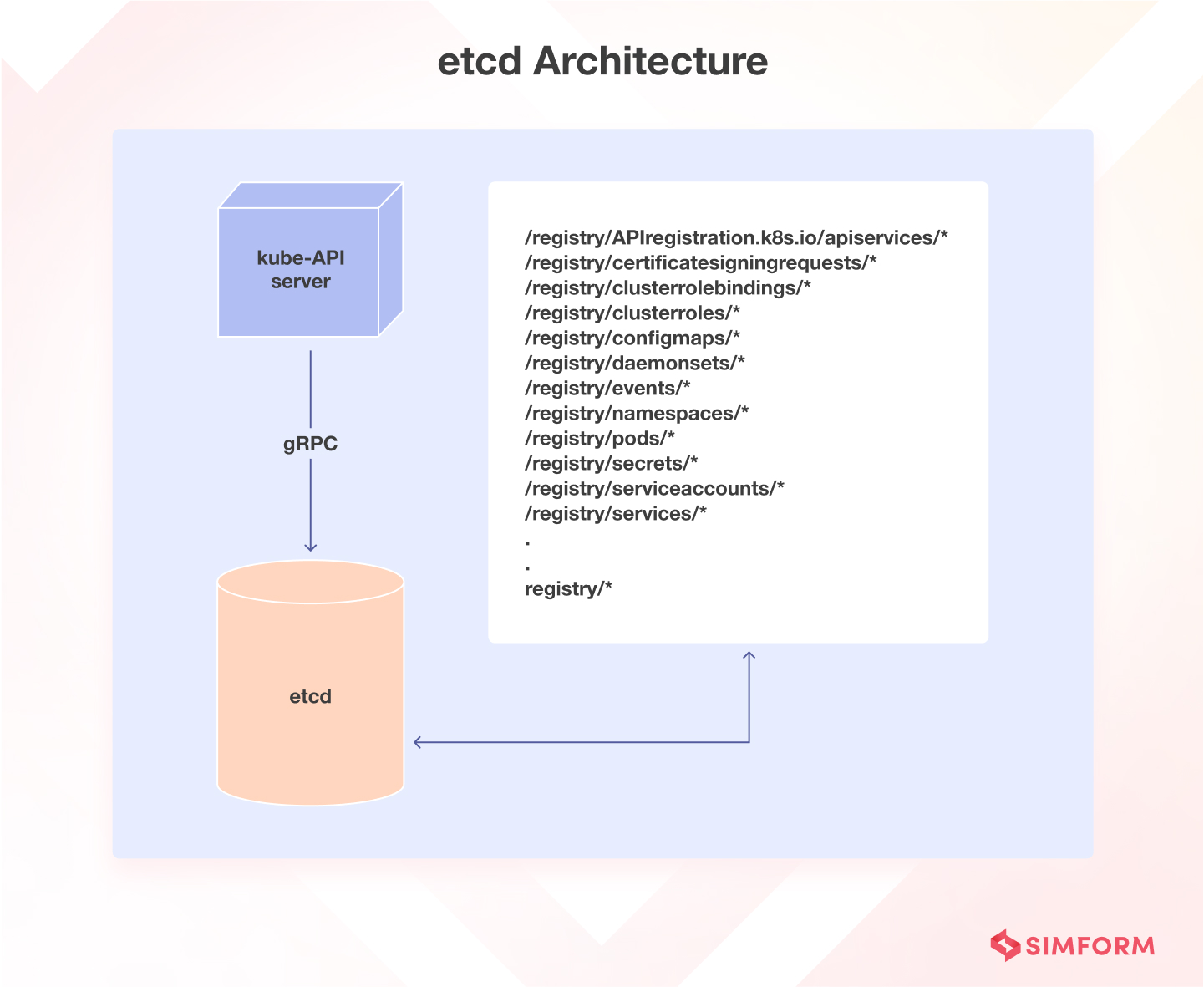
(Image source: https://www.simform.com/blog/kubernetes-architecture/)
역할:
- 분산 키-값 저장소로, Kubernetes 클러스터의 모든 상태 데이터를 저장합니다.
- 영구 저장소로, 클러스터의 상태 정보를 신뢰성 있게 저장합니다.
상세 설명:
- 데이터 저장소: etcd는 클러스터의 모든 구성 요소와 리소스의 상태 정보를 저장하는 분산 데이터베이스입니다.
- 고가용성: 클러스터링을 통해 고가용성과 데이터 일관성을 유지합니다.
- 키-값 쌍: 모든 데이터는 키-값 쌍의 형태로 저장되며, 빠른 검색이 가능합니다.
3. 컨트롤러 매니저 (kube-controller-manager)

(Image source: https://www.simform.com/blog/kubernetes-architecture/)
컨트롤러의 동작 원리
- 컨트롤러는 주기적으로 API 서버에서 리소스의 현재 상태를 읽고, 이를 원하는 상태와 비교합니다. 만약 현재 상태가 원하는 상태와 일치하지 않으면, 컨트롤러는 필요한 조치를 취하여 일관성을 유지합니다.
- Deployment Controller, DaemonSet Controller 등
(예시) Deployment Controller
목적:
- 애플리케이션 배포와 관리를 위해 사용됩니다.
- 여러 복제본의 애플리케이션을 배포하고, 배포 전략을 적용하여 점진적인 롤아웃(rollout)이나 롤백(rollback)을 지원합니다.
특징:
- 복제 관리: 지정된 수의 Pod 복제본이 항상 실행되도록 보장합니다.
- 전략적 배포: RollingUpdate, Recreate 등의 배포 전략을 지원하여 애플리케이션을 무중단으로 업데이트할 수 있습니다.
4. 스케줄러 (kube-scheduler)
역할:
- 생성된 Pod을 적절한 워커 노드에 할당합니다.
- 클러스터의 리소스 사용을 최적화하고, Pod의 요구 사항을 만족시키는 노드를 선택합니다.
상세 설명:
- 노드 선택: 스케줄러는 클러스터 내의 모든 노드의 상태와 리소스 사용량을 고려하여, 각 Pod에 가장 적합한 노드를 선택합니다.
- 리소스 요구 사항: 각 Pod의 리소스 요구 사항(CPU, 메모리 등)을 고려하여 노드를 선택합니다.
- 스케줄링 알고리즘: 다양한 스케줄링 알고리즘을 사용하여 최적의 노드를 선택합니다.
5. kubelet
(Image source: https://www.theserverside.com/blog/Coffee-Talk-Java-News-Stories-and-Opinions/compare-Kubernetes-kubectl-vs-kubelet-when-to-use
역할:
- 각 워커 노드에서 실행되며, API 서버와 통신하여 Pod을 실행하고 상태를 보고합니다.
- 노드에서 컨테이너를 관리하고, 실행 상태를 모니터링합니다.
상세 설명:
- Pod 실행:
- kubelet은 API 서버로부터 받은 Pod 정의를 실행하고, 컨테이너 런타임을 통해 실제 컨테이너를 관리합니다. kubelet은 Pod 정의를 기반으로 컨테이너를 생성하고 필요한 설정을 적용합니다.
- 상태 보고:
- 주기적으로 API 서버에 노드와 Pod의 상태를 보고하여 클러스터의 최신 상태를 유지합니다. 이를 통해 관리자는 클러스터의 상태를 실시간으로 모니터링할 수 있습니다.
- Health check:
- 노드와 Pod의 상태를 모니터링하고, 문제가 발생하면 이를 보고합니다. kubelet은 컨테이너 런타임과의 gRPC 기반 CRI 통신을 통해 컨테이너의 상태를 지속적으로 확인하고, 필요한 경우 재시작 등의 조치를 취합니다.
여기서 잠깐, CRI(container runtime interface)와 OCI(open container Initiative) 스펙에 대해서

(Image source: https://www.simform.com/blog/kubernetes-architecture/)
kubelet의 역할
- 컨테이너 런타임과의 통신: kubelet은 컨테이너 런타임과 상호 작용하여 컨테이너를 생성, 시작, 중지, 삭제합니다. 이를 위해 CRI를 사용합니다.
CRI (Container Runtime Interface). 참고자료
- 표준 인터페이스: CRI는 kubelet과 컨테이너 런타임 간의 상호 작용을 표준화하는 인터페이스입니다. 이를 통해 다양한 컨테이너 런타임을 Kubernetes와 통합할 수 있습니다.
- gRPC 기반 통신: CRI는 gRPC를 사용하여 kubelet과 컨테이너 런타임 간의 통신을 수행합니다.
- 유연한 런타임 지원: CRI를 사용하면 Kubernetes는 Docker, containerd, CRI-O 등 다양한 컨테이너 런타임을 지원할 수 있습니다.
OCI (Open Container Initiative) https://opencontainers.org/
- 표준 정의: OCI는 컨테이너 형식과 런타임에 대한 개방형 표준을 정의합니다. 주요 표준에는 OCI Runtime Specification과 OCI Image Specification이 포함됩니다.
- 호환성 보장: OCI 표준을 따르면 다양한 컨테이너 런타임이 일관되게 동작할 수 있습니다.